Food Tracking & Health Impact Analysis
Overview
A few years ago, I realized that after eating certain foods, I sometimes feel bad, have headaches, or get very sleepy. After discussing this with a colleague, he advised me to start tracking my food intake and how I feel. For the first few weeks, I was doing it in Excel and then decided to use my knowledge and build something fun. This project serves to better understand the impact of food on my health and also as a playground for new technologies, processes, and architectures (e.g., I tried for the first time to code with AI assistance - Claude Code).
I hope this project can help you as it helped me. Happy to receive feedback and ideas.
You can try it out if you want, but be aware that data is publicly available and not properly secured or backed up.
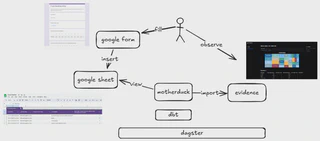
Architecture
The idea is very simple: collect data with a user interface, save data to a database, enrich data, visualize, and extract insights.
(Welcome to data engineering :)
Components
Food collection survey
You can enter as many entries as you have meals per day. The only personal information required is an email, which you can fake if you want to stay anonymous. I normally submit a new entry with only the food name and picture, then after 1-2 hours I add a self-assessment of the health impact. You will receive a confirmation email after the first submission and can edit it later.
Rules I follow
- Log all food consumed in one meal in a single row
- Add self-assessment 1-2 hours after the meal
- Avoid eating other food for at least 3-4 hours after the meal
Visualization dashboard
Your email is hashed, and you can find your hash with the following statement
SELECT left(hex(sha256('123@gmail.com')), 12) as user_hash_id;
You can then search for your user and click in the table to get to your personal dashboard.
The dashboard needs a bit more love and will get it soon.
Status
I will update the status and direction of the project here from time to time.
2026-01-05 The application is working and giving value, but…
Features
- new collection method with Telegram chat/bot
- multiple AI model integrations with the image in the prompt for better prediction results
- refined visuals and also added prompt that can be copy-pasted into ChatGPT for some relation findings
- everything is deployed on my small PC at home with self-hosted runners (let’s see what will be with them)
Learnings
- The bottleneck in development is requirements and feedback collection. You have to find somebody who will use it and openly discuss feedback on your work. My GF started to use the application and immediately said Google Forms is not convenient for collecting entries (I implemented a Telegram chat method) or she also wanted to see proteins (I added proteins in the overview). It is very important to have somebody who will give you honest feedback.
- Claude Code can do everything with web and code base searching as you would do but much more effectively. The first prompt with listing and pointing towards needed code changes and listing everything that has to happen is very important
- A very fast development cycle and feature development created a lot of code that is not really well connected and abstracted. I started to think that we introduced abstractions and best code practices for us humans to lower cognitive load and enable easy extensions of the code. For AI assistant this doesn’t matter it just crunches through.
- I never remembered to commit and push single feature changes -> I know this will hurt me someday
- Adding another data collection mechanism and new data like proteins in the meal made me realize that the data structures and modeling are missing for extendability. AI assistant is just adding a new column, a migration part in the init statement and it is done but it hurts stability.
- Dagster components are very convenient to use and develop
next steps
- try to get a few people using the application and collect feedback
- stabilization of the code
- introduce ty, refactor code in smaller modules
- introduce a base image for building images in CI/CD
- improve Dagster-Evidence integration and contribute to open source
2025-12-24 - Init
Overall
The general idea was to set up an initial UI for data collection, basic Dagster, dbt, and MotherDuck integration (I know about Dagster and dbt from my work), and have a basic dashboard with a few metrics and visualizations. I had a few things in mind that I wanted to learn with the first iteration:
- How to use Google Forms as a data collection UI (I was surprised by the out-of-the-box features like saving and editing entries in Google Sheets, and sending email confirmations)
- Try to code with AI assistance - Claude Code blew my mind a few times
- Deploy Dagster on a self-hosted Kubernetes cluster with a self-hosted runner (it was harder than expected)
- Connect and explore MotherDuck as I wanted to get back to DuckDB
- Learn a new visualization tool (I decided on Evidence because it already had a Dagster integration, though I now think it’s not mature and needs improvement that I’ll try to contribute)
Learnings
- The process around building Docker images and deployment with self-hosted GitHub runners on a self-hosted Kubernetes cluster requires a lot of knowledge that we often take for granted when we have DevOps colleagues
- Starting simple with visible business value is more important than sophisticated tooling. For example, I now use Google Forms to collect data instead of building a custom UI in Rust (I started and stopped at least 3 times)
- Having a working end-to-end solution for the first time was very motivating and helps extend and improve it further
- It is hard to collect data and be precise. What exactly is in the meal? How do you really feel on a scale from 1 to 10?
Next Steps
- Create more dashboards and visualizations from the existing data
- Enrich collected data with AI-generated ingredients from food name and picture
- Find more friends who are willing to try this out
- Try SOPS for secrets and FluxCD for Kubernetes deployment
- Try to improve the Dagster-Evidence component integration
- Make refreshes run automatically on a schedule
