WTF Memory - Istraživanje korišćenja memorije
Pregled
Edukativni repozitorijum za učenje o korišćenju memorije u data bibliotekama koristeći memray profiler. Uključuje primere učitavanja i obrade podataka sa bibliotekama kao što su DuckDB, Apache Arrow i Delta Lake, kao i razmenu podataka između njih.
Ovaj projekat je počeo kao pokušaj da se poboljša dbt-duckdb integracija sa Delta tabelama razumevanjem potrošnje memorije tokom razmene podataka između DuckDB-a i Delta writer-a putem Arrow formata. Lepa vizualizacija alokacije memorije tokom prenosa podataka između DuckDB-a i Delta Lake-a putem Arrow formata može se pronaći ovde.
Naučene lekcije
- dbt samo šalje SQL komande bazi podataka, a upiti nisu uvek optimizovani za efikasnost memorije
- Arrow je veoma koristan, a DuckDB mora da ga obezbedi kao iterator pozivaocu jer buffer manager može da razmenjuje blokove memorije i zato fiksni pokazivači ne rade
- Promene u open source projektu moraju biti male i inkrementalne da bi bile prihvaćene. Uložio sam mnogo vremena ali nisam mogao da osiguram kompatibilnost unazad i zato moj PR nije prihvaćen
- Memray je odličan i njegova grafička reprezentacija pomaže da se vizualizuje korišćenje memorije i razume šta radite pogrešno u programu
- Razumevanje korišćenja RAM memorije je važno za performanse data aplikacije
Povezani tvitovi
Doing some baby unscientific experiments with different code flows while exporting for the dbt-duckdb
— Aleksandar Milicevic (@milicevica23) March 4, 2024
We are particularly interested in the difference between b (current flow) and c (potentially a new flow) #duckdb pic.twitter.com/0W0HG52lKQ
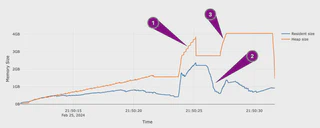
Playing around with memray and delta-rs and i am not sure if i understand what i see
— Aleksandar Milicevic (@milicevica23) February 25, 2024
1. Why is .arrow() not stable but it takes around 1 GB?
2. What is happening with resident memory?
3. if we give arrow format to delta writer it copies data again? pic.twitter.com/fg38REN8fw
